
Evaluating LLMS: LLM as a Judge
Published:
Problem Statement
There are a lot of open source models out in the wild. I’d like to know which model performs best to my dataset. I’d like to evaluate based on accuracy, relevance and hallucination. Use only open source models locally without OpenAI and spending a cent.
Approach
Let’s visualize what we’ll be working on.
- Given a dataset, we’ll run them through a smaller 1B parameter models and generate their responses.
- The recorded responses will then be Judged using a 8B parameter LLM.
- Visualize the results.
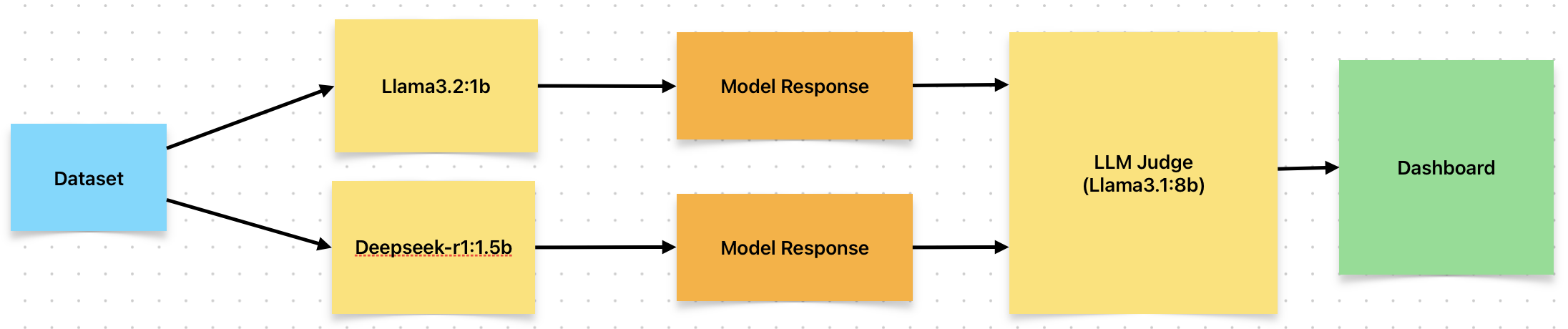
Dataset
The Human-Like-DPO-Dataset was developed as part of research aimed at improving conversational interactions in LLMs. Comprising 10,884 samples across 256 distinct topics—ranging from Technology to Arts—this dataset serves multiple purposes:
- Conversational Question: A natural, engaging question designed to mirror everyday human dialogue.
- Human-Like Response: A conversational answer intended to mimic human interaction, emphasizing warmth and relatability.
- Formal Response: A structured, professional response that reflects traditional AI output. The dataset is particularly useful for formats like Direct Preference Optimization (DPO), which guides models to generate responses that are more human-like and engaging.
Large Language Model (LLM) Runtime: A Critical Consideration for ML Engineers
As machine learning engineers, we strive to harness the full potential of Large Language Models (LLMs) in our applications. However, deploying LLMs efficiently requires careful consideration of runtime strategies. This post explores two primary approaches to accessing LLMs: API-based integration and local deployment.
Groq
One popular solution for leveraging LLMs is through an API-based approach. Groq offers a free, limit-based tool that grants access to 70B parameter models at no cost. While this option provides a generous allocation of compute resources, it comes with limitations – specifically, a capped number of requests per second. For projects requiring high-throughput processing, Groq’s limitations may be restrictive.
Groq: A Compromise Solution
If budget is a concern but high-performance processing is essential, consider supplementing Groq’s free tier with paid services. By doing so, you can unlock increased request rates and eliminate API-based limitations while still benefiting from the generous allocation of 70B parameter models provided by Groq.
In conclusion, when designing LLM runtime strategies, it’s crucial to weigh the trade-offs between API-based integration and local deployment. While each approach offers unique benefits and drawbacks, understanding these considerations will empower you to make informed decisions tailored to your project’s specific requirements.
LiteLLM
LiteLLM provides a simple and unified interface to various LLM models, allowing developers to easily integrate them into their applications. It supports Azure, OpenAI, Amazon Bedrock, Google Gemini and Anthropic Claude models.
It also provides support for locally running LLMs through Ollama. It also supports observability when deploying your LLM application to the cloud through various providers like Langfuse, mlflow and many more.
Local LLM Runtime Approaches
For applications demanding greater control and flexibility, running LLMs locally presents an attractive alternative. By hosting the model on-premises or in a cloud environment under your management, you can sidestep API-based constraints and tailor the deployment to your specific needs. However, this approach often incurs additional costs associated with infrastructure and maintenance.
Ollama
A very popular open source tool to LLMs locally. It comes with a simple CLI and support hugging face models too. Ollama supports some of the most popular open source models which can be viewed here. Deepseek-r1 is currently available through Ollama.
To view all commands
To view all running models

To view all models currently downloaded

vLLM
vLLM is an open-source library designed for efficient inference and serving of large language models (LLMs). Developed initially at UC Berkeley’s Sky Computing Lab, it has evolved into a community-driven project with contributions from both academia and industry. vLLM introduces the PagedAttention algorithm, which optimizes memory management of attention key and value pairs, resulting in state-of-the-art serving throughput. It offers seamless integration with popular Hugging Face models and supports various hardware platforms, including NVIDIA GPUs, AMD CPUs and GPUs, Intel CPUs, Gaudi® accelerators, and more. Key features include continuous batching of incoming requests, support for multiple quantization methods (such as GPTQ, AWQ, INT4, INT8, and FP8), and compatibility with various decoding algorithms like parallel sampling and beam search. Additionally, vLLM provides an OpenAI-compatible API server, making it a versatile choice for deploying LLMs in diverse environments.
A quick look in the mirror
For our problem statement of evaluating LLMs, we considered using API based approaches and running LLMs locally. For API based approaches, we looked at Groq and litellm. Groq is free under certain limits and litellm provides a unified interface to different LLM but these may result in charges over time when considering scaling your application.
To run LLM models locally, we looked at Ollama and vLLM. vLLM offers more features compared to Ollama. Though we haven’t implemented anything yet, it is necessary to know what are the tools available to my disposal, what approaches meet my objective.
As I move forward in my evaluation of LLM strategies, it’s clear that each approach has its strengths and weaknesses. By understanding these trade-offs, I can make informed decisions about which methods best suit my objectives.
Action
Given a dataset, we’ll run them through a smaller 1B parameter models and generate their responses.
Dataset
The Human-Like-DPO-Dataset is a pretty simple dataset containing 10884 entries with each entry containing a prompt, a Human like DPO response and a generic response from a LLM.
{
"prompt": "Oh, I just saw the best meme - have you seen it?",
"chosen": "😂 Ah, no I haven't! I'm dying to know, what's the meme about? Is it a funny cat or a ridiculous situation? Spill the beans! 🤣",
"rejected": "I'm an artificial intelligence language model, I don't have personal experiences or opinions. However, I can provide you with information on highly-rated and critically acclaimed films, as well as recommendations based on specific genres or themes. Would you like me to suggest some notable movies or discuss a particular genre of interest?"
}
One of the reasons for choosing this dataset is that it provides less friction with respect data transformations so that we can focus our efforts more towards the LLM evaluation.
Generating response
Given a dataset, we’ll run them through a smaller 1B parameter models and generate their responses.
We’ll use Ollama to run 1B models and generate responses. Currently, llama3.2, qwen, qwen2 have 1B models. Since Deepseek is the new kid on the block we’ll use deepseek-r1’s 1.5B model as well to generate responses.
Note, even though the dataset contains already LLM generated responses, we are want to explore how to generate such responses locally.
We’ll be using llama3.2:1b and deepseek-r1:1.5b models through Ollama.
For installing Ollama, please refer Ollama
To run llama3.2:1b
ollama run llama3.2:1b
To check whether the model is running
ollama ps

You should be able to see this if your installation went correctly.
P.S: I’m running this on a Macbook pro m1 with 16GB unified RAM.
The same way, to run deepseek-r1:1.5b model,
ollama run deepseek-r1:1.5b
You should be able to see this if everything went well.

We’ll write a script such that the models are used sequentially instead of loading both the models in the GPU.
Generate Responses
First, we’ll have to write a script to interface with the models running using Ollama. This will make our life easier.
There python class need two methods.
- To generate the raw response
- To generate a structured response
I’ll explain why need a structured response in a while.
class LLMClient:
def __init__(self, client_type: str = "ollama", model_name: str = "llama3.2:1b"):
self.client_type = client_type
self.model_name = model_name
self.instructor_client = None
self.model = f"{client_type}/{model_name}"
def llm_output(
self, query: str, evaluation_prompt: str = "You are a helpful assistant."
):
response = None
messages = [
{"role": "system", "content": evaluation_prompt},
{"role": "user", "content": query},
]
try:
response = completion(model=self.model, messages=messages)
if response is not None:
return response.choices[0].message.content
except Exception as e:
print(f"something went wrong")
print(e)
return response.choices[0].message.content
def output_with_tool(
self,
query: str,
custom_response_model,
evaluation_prompt: str = "You are a helpful assistant.",
):
response = None
messages = [
{"role": "system", "content": evaluation_prompt},
{"role": "user", "content": query},
]
try:
instructor_client = instructor.from_openai(
OpenAI(base_url="http://localhost:11434/v1", api_key="ollama"),
mode=instructor.Mode.JSON,
) #
response = instructor_client.chat.completions.create(
model=self.model_name,
messages=messages,
response_model=custom_response_model,
)
return response
except Exception as e:
print(f"Something wrong with Ollama client: {e}")
print(e)
return response
The llm_output method returns the raw output from the LLM. This method will be used to generate the response.
The output_with_tool method uses a response model which parses the output of the LLM to a Pydantic class and extracts the necessary fields required.
Wait, Why? How?
The instructor library provides a way to parse and structure the output from LLMs in a more meaningful way, making it easier to work with the generated text. Here are some reasons why you might want to use an output parser like instructor:
Structured Output: LLMs typically produce plain text output, which can be difficult to process and analyze programmatically. By using an output parser, you can convert this plain text into a structured format (e.g., JSON or Python objects) that’s easier to work with.
Extracting Relevant Information: When interacting with LLMs, it’s often not the entire response that’s useful but rather specific parts of it. An output parser can help extract relevant information from the generated text, such as answers, supporting evidence, or other key points.
Improving Accuracy and Reliability: By parsing the output from an LLM, you can improve its accuracy and reliability. For example, if an LLM provides a response with multiple possible answers or suggestions, an output parser can help identify the most relevant or accurate ones.
Enhancing Integration with Other Tools: Many tools and libraries expect structured input/output formats to function properly. An output parser like instructor can facilitate integration with these tools by providing the necessary formatting and structure.
Support for Advanced Features: Some LLMs offer advanced features, such as highlighting or summarization, which require parsing of the generated text. An output parser can help leverage these features by extracting relevant information from the response.
So now that we have an interface ready to generate responses, let’s write another script which will load the model, generate the responses on the prompt from our dataset and save the data to a csv file. We can circle back to exploring and saving the results in different formats at a later time. Right now, let’s move ahead.
Script to generate responses
def get_json_data(file_name: str):
with open("data.json", "r") as f:
data = json.load(f)
return data
def generate_llm_output(llm_client, data):
results_list = []
for data_point in tqdm.tqdm(data):
results = {}
prompt = data_point.get("prompt", None)
llama_response = llm_client.llm_output(query=prompt)
results["prompt"] = prompt
results["llama_response"] = llama_response
results_list.append(results)
return results_list
def save_results(results, file_name):
df = pd.DataFrame(results)
df.to_csv(f"{file_name}.csv", index=False)
if __name__ == "__main__":
models = ["llama3.2:1b", "deepseek-r1:1.5b"]
for model in tqdm.tqdm(models):
llm_client = LLMClient(client_type="ollama", model_name=model)
data = get_json_data("data.json")
results = generate_llm_output(llm_client, data)
print(f"saving results: {model}-responses")
save_results(results, f"{model}-responses")
Moving on…
The recorded responses will then be Judged using a 8B parameter LLM.
Why use a larger model as a judge to evaluate the performance of smaller models?
A larger model is often used as a “judge” or evaluation baseline for smaller models due to several reasons:
- Better Generalization: Larger models have been trained on more data, which enables them to generalize better across various tasks and datasets. They can recognize patterns and relationships that may be difficult for smaller models to detect.
- More Comprehensive Knowledge Base: A larger model has a broader knowledge base due to its extensive training on diverse texts, making it a better representation of the language distribution. This allows it to serve as an evaluation baseline for smaller models, providing a more accurate assessment of their performance.
- Reduced Overfitting: Smaller models are often prone to overfitting, where they become too specialized in the specific task or dataset and fail to generalize well to new data. A larger model can help mitigate this issue by serving as an evaluation baseline that has seen a broader range of tasks and datasets.
- Reducing Model Selection Bias: When using a smaller model for evaluation, there’s a risk of selection bias – where the evaluation results are influenced by the specific characteristics or features of the smaller model. A larger model can help reduce this bias by providing an unbiased evaluation baseline that is less dependent on the smaller model’s properties.
- Improved Evaluation Metrics: Larger models tend to have more accurate and reliable evaluation metrics, such as perplexity scores or ROUGE scores. These metrics provide a more comprehensive understanding of a model’s performance, allowing for better comparisons between different models.
By using a larger model as an evaluation baseline, researchers and developers can:
- Evaluate smaller models’ performance in a more robust and comprehensive manner.
- Identify areas where smaller models may be struggling to generalize or capture key knowledge.
- Fine-tune smaller models to improve their performance and adapt them to specific tasks or datasets.
This approach enables the development of more accurate and reliable evaluation methods, ultimately leading to better-performing language models.
okay.. how shall we do it?
The same way we did before but with some minor changes.
In the previous code, when designing the LLMClient class, we wrote a method called output_with_tool. If you paid attention to the parameters passed to that method, we passed in a custom response model and an evaluation prompt. This evaluation prompt will play a key role in evaluating the response generated to the prompt.
Let’s visualize
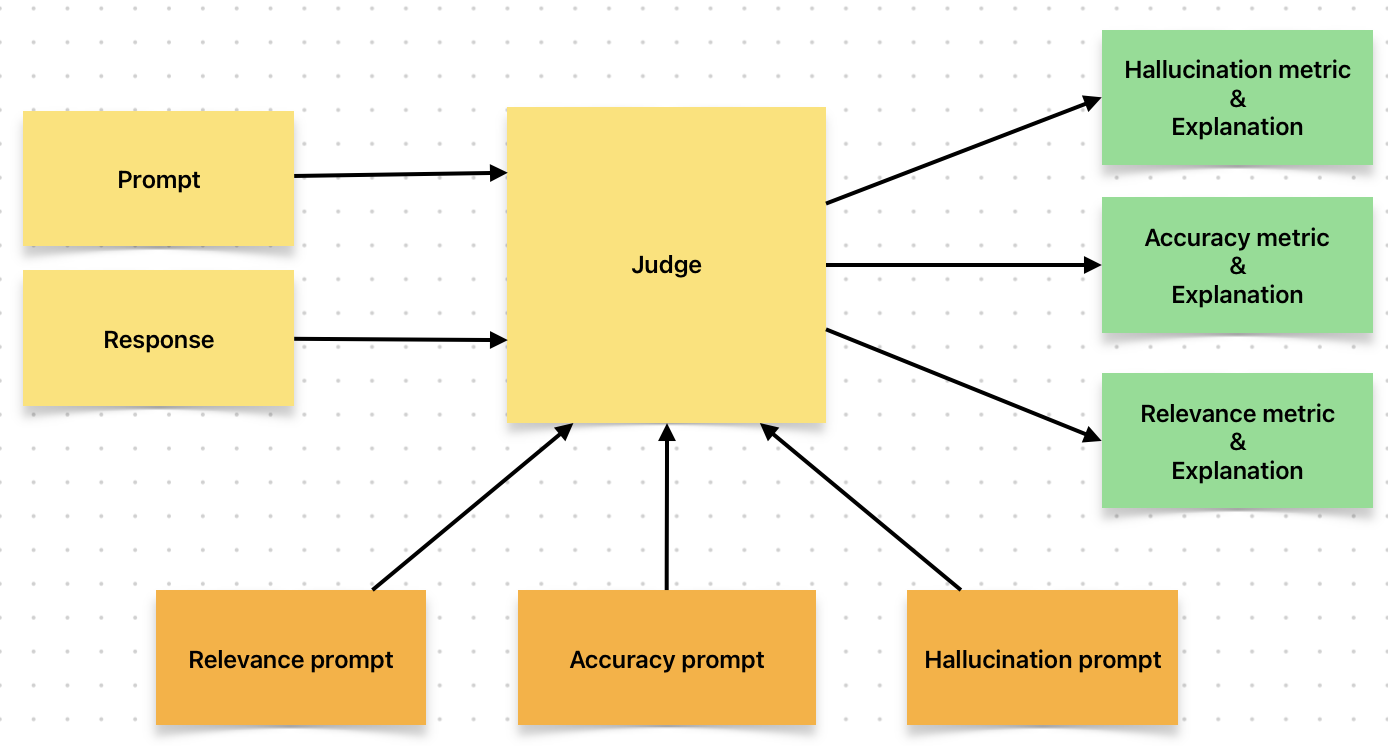
Here’s the rephrased text to be added to a blog:
Evaluating Model Performance: The Judge’s Role
To assess the quality of our LLM’s responses, we take an extra step by using a much larger LLM in a new capacity - as a judge. We prompt the judge model with the same input that generated the response, as well as the response itself. This time, however, we configure the system to evaluate the response from a critical perspective.
By doing so, our LLM is tasked with assessing its own performance, providing valuable insights into:
- The relevance of its generated response to the original prompt
- The accuracy of its response in addressing the user’s query
- Whether it has “hallucinated” information that isn’t supported by the input data
This approach allows us to gauge our model’s strengths and weaknesses, ultimately refining its performance and producing more accurate and informative responses.
In this case, we choose a llama3.1 8B model as our judge since it is available in Ollama.
Evaluator
Let’s build an Evaluator based on the above diagram which will utilize the LLMClient class which we’ve seen earlier. The Evaluator will have methods to evaluate each of the following metrics: relevance, accuracy and hallucination.
To enhance the efficacy of our response evaluation, we propose utilizing more advanced reasoning models to generate comprehensive evaluation prompts. The carefully crafted nature of these prompts is essential in ensuring the accuracy and reliability of our assessment process.
Following an iterative approach that involved extensive trial and error with larger language models, I have developed a set of highly detailed evaluation prompts using DeepSeek. These prompts were designed to capture nuanced aspects of the response and serve as a benchmark for evaluating its quality and relevance.
We will now configure the Evaluator’s system behavior to utilize the refined prompts, enabling it to effectively assess the output from the previously developed models.
The evaluation prompts are in the evaluation_prompt.py file of the codebase.
This post is getting too long. I will continue the execution and other aspects in a following post.